What Is Next Generation Sequencing (NGS) And How Is It Used In Drug Development

NGS methodologies have been used to produce high-throughput sequence data. These data with appropriate computational analyses facilitate variant identification and prove to be extremely valuable in pharmaceutical industries and clinical practice for developing drug molecules inhibiting disease progression. Thus, by providing a comprehensive profile of an individual’s variome — particularly that of clinical relevance consisting of pathogenic variants — NGS helps in determining new disease genes. The information thus obtained on genetic variations and the target disease genes can be used by the Pharma companies to develop drugs impeding these variants and their disease-causing effect. However simple this may allude to, determination of genetic mutations and drug target genes requires population-scale NGS analyses and focused analyses on clinical trials to identify biomarkers for drug efficacy or safety.
Diverse NGS methods such as Whole Genome Sequencing (WGS), Whole Exome Sequencing (WES), transcriptome sequencing, and targeted sequencing can be used to perform molecular profiling, and to discover novel drug biomarkers or targets. Among these methods, WGS detects whole-genome mutations, WES focuses on only 1-2% of the entire genome; however, WES covers > 95% of the exons. That is more than the WGS coverage. Transcriptome sequencing is used to profile mRNA expression analysis and detect non-coding RNAs. With the help of high sequencing depth and exon coverage, Targeted Sequencing is useful in detecting rare variants.
In addition to the aforementioned sequencing methods, bisulfite sequencing, ribosome profiling, and Chip-sequencing have proved to be of vital importance for drug development and clinical practice (a comprehensive and strategic explanation of various sequencing methods is available in the “ExSeq program”). Epigenetic mechanisms such as chromatin remodeling, DNA methylation, and histone modification, involved in the aforementioned sequencing methods are very useful in gene and non-coding RNA expression profiling, which play a vital role in epigenetic drug development. Additionally, many cancer therapies are based on epigenetic drugs. Epigenetic drugs have a few advantages, such as:
a) many diseases are not mutation dependent, but rely on altered levels of expression of epigenetic modulators.
b) these drugs have relatively low toxicity as long as critical thresholds are not crossed.
1. NGS target identification
NGS has the ability to generate enormous amounts of sequence data from disease samples. This data harbor the potential to uncover mutations associated with genetic diseases and to determine target genes for drug development endeavors. To identify these target genes, an Electronic Health Record (EHR) approach coupled with NGS sequencing can be used. There could be two ways to execute this methodology:
a) By leveraging the rich phenotype information from the EHR, the association between variants in candidate drug targets and selected phenotypes of interest can be examined. The application of NGS to well-phenotyped population data in the EHR system is useful in revealing phenotype-specific drug targets for multiple diseases or phenotypic traits simultaneously. This approach can also be called “EHR-based phenotyping and target selection.” This method has an advantage as it depends on the population in the healthcare system and does not require any data collection for specific phenotypes. Also, target genes belonging to multiple phenotypes can be concurrently determined. Moreover, it constitutes the discovery of pathogenic and likely to be pathogenic germline mutations from population-wide studies.
b) Another approach could be to choose the desired phenotypic trait based on its frequency and relevance. NGS sequencing is performed on the cohort of specific phenotypes of therapeutic implications and then highly penetrant genetic targets for the trait of interest are identified. Although the approach demands initial effort in determining the cohort, it brings forth the pros of a strategic implementation for determining highly targeted genes and variants that could be used for personalized drug development in pharmacogenomics studies.
Thus, NGS can significantly expedite the determination of individuals that carry mutations in the gene for clinical trials. Consequently, helping the care-providers and pharma companies in identifying patients who are suitable for specific drugs.
2. NGS in pharmacogenomics
Pharmacogenomics is the study of the efficacy of drug response in an individual and the extent to which it varies among individuals based on genomic content. It also explores how genotype-phenotype information can be used in personalized medicine. Research conducted in the biomedicine field has reported variants from different somatic and germline domains.
However, it is pertinent to understand that just the discovery of novel variants does not apprehend the variability in an individual’s disease management. The realistic application of genomic findings goes beyond variant identification and variation in clinical trials. A comprehensive set of stages to integrate next-generation sequencing into clinical pharmacogenomics is imperative to better understand disease management and envision personalized medicine.
The stages are:
(i) identification of pharmacogenomic gene targets and their validation in controlled studies with independent population cohorts.
(ii) replication and understanding of the drug-gene(s) association mechanism and demonstration of utility in patients at-risk.
(iii) development of clinical diagnostic tests and their regulatory approval.
(iv) assessment of the clinical impact and cost-effectiveness of the pharmacogenomic gene targets.
(v) involvement of stakeholders in clinical execution.
Genotyping And Data Analysis In Pharmacogenomics
With the plunging cost of genotyping or sequencing, more and more academic institutions and private organizations are engaging in collaborative programs to focus on NGS of disease-case genomes, such as cancer genome — aiming to describe the architecture of the disease-specific alterations and aid clinicians in disease management. We have touched base at the beginning of this article about the various types of NGS methods and their implications in identifying drug targets.
Although every sequencing methodology has its advantages in identifying variants characterized by their phenotypic and clinical variability, in pharmacogenomics, targeted gene sequencing seems to be more relevant compared to other sequencing methods such as WES. The reason being the ability of this method to capture genetic variants that are present in genomic positions other than the exons, such as the intronic and untranslated regions, that can lead to a substantial reduction of drug metabolizing enzyme activity. These rare pharmacovariants are of utmost importance in personalized drug therapy as they provide information to avoid adverse drug reactions and lack of response. Furthermore, compared to Sanger Sequencing, NGS yields more accurate quantitative results that can be achieved at a higher throughput scale.
Variant Data Prioritization And Interpretation
After getting the variant data, comes the prioritization and interpretation of the discovered variants. This is an integral part of pharmacogenomics that is not well incorporated and interpolated in clinical settings which leads to the slow uptake of pharmacogenomics in clinical labs. The salient aspects that influence pharmacogenomics translation into clinical practice are:
- interpretation of published variant data results, and;
- interpretation of reported genetic variant results.
Considering the usage-rate of pharmacogenomics implementation in clinical labs, it is evident that, although a majority of the researchers/clinicians acknowledge the effect of genetic variants in drug response only a limited number show adequate information about pharmacogenomics data interpretation relevance. The way to overcome this gap and further the integration of variant data interpretation in labs is by collaborating and accumulating NGS data, as large sample sizes would help to maximize the clinical benefits by retrospectively analyzing large patient cohorts. This strategy will prove useful in:
- determining common and rare variants
- validation
- diagnosis and decision-making from accumulated variant data
Efficient assembly, mining, and analysis of the accumulated multi-faceted data are necessary to make clinically significant diagnoses. To facilitate the decision-making process, a collaborative web-based support platform adopting a hybrid approach of synergy between computer-algorithms and human intellect can be used. Such platforms can be called “Clinical Decision Support (CDS)” tools. An example of such a tool is Agilent Technologies’ “Alissa Interpret” — a clinical informatics platform for molecular pathology and clinical genetics labs to standardize and automate variant triage, review, classification, and reports on clinical NGS and CGH data, and eventually assist in making clinical diagnoses.
Accreditation And Consultation
Application of pharmacogenomics in drug or personalized medicine development requires proper accreditation of genome data quality and NGS assays design because of its vital influence in medicine and biomedical research.
To ensure the quality of medical products and services, medical agencies have been set up in countries. For example, European Medicines Agency (EMA) has defined regulatory frameworks for:
- Good Clinical Practice (GCP) compliance
- Good Laboratory Practice (GLP) compliance
- Good Manufacturing Practice (GMP)
- Good Distribution Practice (GDP)
- Good Pharmacogenomics Practice (GPP)
The guidelines in these frameworks stress the importance of the steps included in NGS protocol from DNA isolation to variant identification, annotation, and interpretation. For example, the guideline gives the information that the minimum sequencing coverage for germline pharmacovariants should be 30x, whereas, for rare variants, it should be higher to ensure that rarer variants are also detected by sequencing.
Next comes the consultation, where regulatory compliances are used to eliminate the uncertainties about the ways pharmacogenomics results can be translated into clinical care decisions by the government agencies. As per the United States Food and Drug Administration (FDA) policy, all relative information available for a pharmacogenomics product should be made available to ensure that patient care is not compromised.
Consequently, PharmGKB was established — it is a curated database constituting information on drug properties, pathway diagrams, and related publications. Users can query for drugs, genes, or diseases to obtain relevant data. In addition to PharmGKB, Dutch Pharmacogenetics Working Group (DPWG) and Clinical Pharmacogenetics Implementation Consortium (CPIC) were also deployed to assist healthcare professionals in interpreting pharmacogenomic testing results and in making efficient diagnoses.
The clinical pharmacogenomics workflow can thus be described in the following steps:
- NGS or genotyping using WGS, WES, or Targeted sequencing performed by accredited laboratories.
- Variant discovery in pharmacogenes and other genes involved and related to drug metabolism.
- Pharmacogenomic variant data prioritization, where the identified variant is given a score based on certain criteria such as:
- Novelty of variant
- Nature of the variant (frameshift, non-synonymous, synonymous, etc.)
- Variant’s frequency (common or rare)
- Existing evidence of the variant in drug metabolism from databases like PharmGKB and CPIC.
- Variant interpretation based on the scientific literature, databases, and algorithms in association with the recommended databases like CPIC and PharmGKB.
- Pharmacogenomics consultation from a qualified experts to provide appropriate advice on the drug choice to avoid adverse reactions.
Proper implementation of the aforementioned workflow for next-generation sequencing-based pharmacogenomic testing and validation is only possible with the synergy of stakeholders in accepting and implementing the current technological advances in the field of NGS.
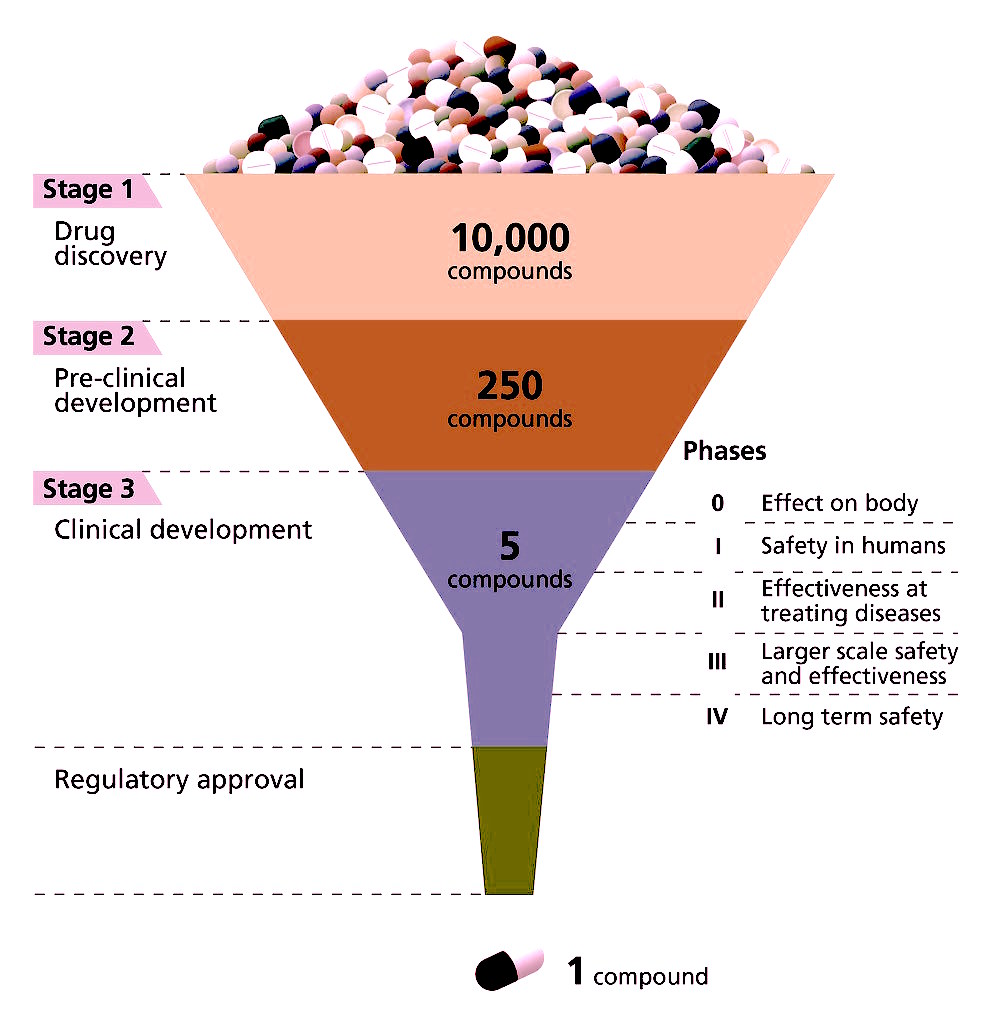
Having covered the pharmacogenomics workflow, let’s move onto the application areas of pharmacogenomics and NGS in clinical trials that are used to understand the efficacy of drugs by following strategic approaches.
A special application area of pharmacogenomics is:
1) Companion diagnostics
These diagnostic tests are used to assess the effectiveness of the drug treatment before the drug is prescribed for disease treatment. In other words, these tests are the “companions” of specific drugs and help understand the drug’s expected efficacy. A list of FDA-approved companion diagnostics devices can be found here. As we see in the list, NGS assays are among the most approved diagnostics devices.
Next comes the clinical trials studies performed using the diagnostic tests devices and strategies to further understand drug therapies:
1) Basket/bucket clinical trials
This is the type of clinical trial in which diagnostics tests are performed in patients that carry different types of cancer having the same mutation/biomarker but with distinct clinical phenotypes. These patients receive the same drug treatment targeting the specific mutation diagnosed to cause cancer. Because of this strategic approach, where all patients are put under the same treatment, the trial method is called “Basket” clinical trial. These clinical trials can also be used to study rare genetic aberrations.
2) Genetically stratified clinical trials
These clinical trials only include patients bearing a specific type of mutation that is more likely to respond to the tested drug. These mutations could be in the same or different genes. An advantage of this method is that it improves the power of trials with a fixed sample size since it recruits only a subset of patients with specific genotypes that are most likely to respond to the drug treatment.
A simple workflow of stratified clinical trials can be represented as below:

Stratification is the process of division of participants into smaller subgroups. It is used to ensure equal allocation of subgroups to each experimental condition based on age, gender, or other demographic factors. And, randomization is the process of randomly assigning participants to separate groups that receive different treatments. In this study, usually there are two groups: the investigational group and the control group. The investigational group receives the new treatment whereas the control group receives the standard therapy. At the end of the clinical trial study, a comparison is made to examine the efficacy of treatments. Randomization helps to prevent bias.
Concluding Remarks
The goal of this article is to give a perspective on how NGS can be used in pharmacogenomics to perform better interpretation and diagnosis of the identified variants/mutations/biomarkers from patients’ data. Usage of the technological advancement in NGS and the extensive patient data available in EHR systems in determining pharmacogenes could help in conducting efficient clinical trial studies to improve the drug treatment efficacy. In the coming years, with the continuous increase and availability of sequencing data and the focus towards pharmacogenes, we will surely see newly developed and marketed drug compounds facilitating personalized drug treatments.
To learn more about gene prediction and how NGS can assist you, and to get access to all of our advanced materials including 20 training videos, presentations, workbooks, and private group membership, get on the Expert Sequencing wait list.

ABOUT DEEPAK KUMAR, PHD
GENOMICS SOFTWARE APPLICATION ENGINEER
Deepak Kumar is a Genomics Software Application Engineer (Bioinformatics) at Agilent Technologies. He is the founder of the Expert Sequencing Program (ExSeq) at Cheeky Scientist. The ExSeq program provides a holistic understanding of the Next Generation Sequencing (NGS) field - its intricate concepts, and insights on sequenced data computational analyses. He holds diverse professional experience in Bioinformatics and computational biology and is always keen on formulating computational solutions to biological problems.
More Written by Deepak Kumar, PhD











